
What is computer vision? Why is it something worth dedicating time and energy to understanding and applying? How does it work? And what applications could it be useful in the business world? If you have yet to find simple-to-understand answers to these questions, then this blog post is for you.
Introduction to Computer Vision
What?
Google: “Well, you should have specified -CLOUD then!” 😠 Source: xkcd
What is computer vision? It is defined as using computers to automatically perform the tasks that the human visual system can do. Where human eyes receive light stimulus from the external environment, computers use digital cameras. Where the brain interprets these sensory inputs, the computer uses an algorithm to interpret the images.
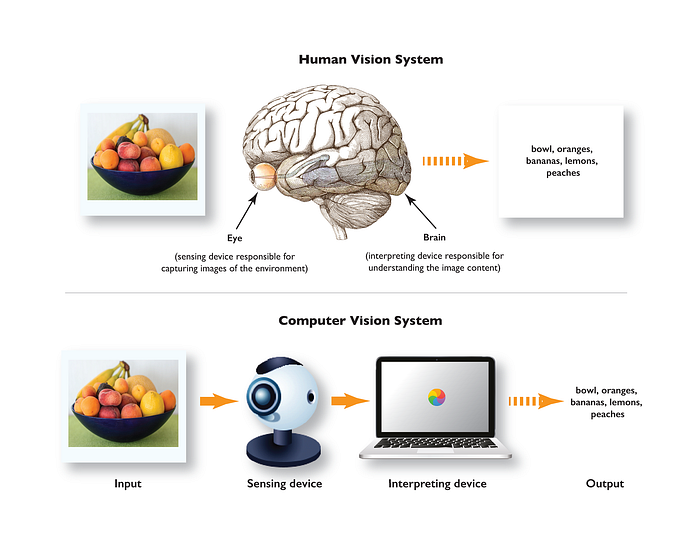
Human 👀 vs. Computer 👀. Source: Medium
Obtaining accurate images of our physical environment with digital cameras has long been solved with our current technology. And for the most part, assigning meaningful labels to objects in these digital images has also been solved in the past decade. The 2012 edition of the ILSVRC (ImageNet Large Scale Visual Recognition Challenge) [1] challenged research teams from across the world to classify the 1000 object classes from the over one million images in its ImageNet dataset. In that year, a deep learning method took first place for the first time in the image classification task.
This deep learning method, named AlexNet [2] (after the first author, Alex Krizhevsky), was developed by a team from the University of Toronto called SuperVision, and utilized a convolutional neural network (CNN) architecture (more on this later) to obtain a top-5 error (i.e. the percentage of wrong top-5 guesses out of 1000 object classes) of 15.315%, compared to the runner-up method’s top-5 error of 26.172% (which used a classical machine learning approach). As machine learning practitioners like to emphasize over and over ad nauseam, this is a 10.857% reduction in error! By comparison, Andrej Karpathy trained himself to do the image classification task and came up with an informal (and unpublished) error of 5.1%. At that time, ILSVRC 2014’s top-performing method, GoogLeNet [3] had already improved to a top-5 error of 6.7%. And as Karpathy himself noted, his less dedicated and less trained lab mates performed much more poorly. Clearly, not all humans have the patience and training for large-scale pattern recognition:
It was still too hard – people kept missing categories and getting up to ranges of 13-15% error rates.
Does this mean that computers are now able to “see” as well as humans can? No, not necessarily.
In 2015, researchers discovered that many state-of-the-art computer vision models are prone to maliciously-designed high-frequency patterns known as “adversarial attacks” [4], which trick the models into modifying their predictions without being visible to humans.
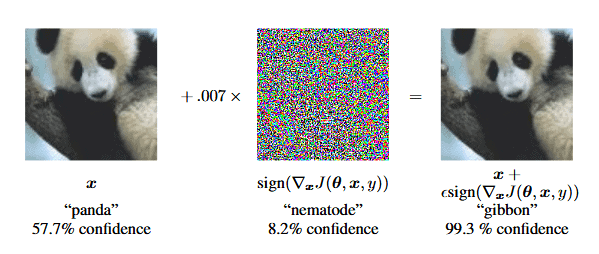

🐢 or 🔫? Depends if a computer vision researcher is pranking you… Source: YouTube
Why?
Ok, but adversarial attacks but highly-specialized researchers aside, why should we care about computer vision? Well, for the same reason that Andrej Karpathy identified – training humans to do fine-grained, large-scale visual recognition requires significant training, dedication, and time. At the end of the day, there will still be human error. From Karpathy’s single experience in competing against computational methods in ILSVRC, he had already dispensed with the idea of:
- Out-sourcing the task to multiple individuals for money (i.e. to paid undergrads or paid labellers on Amazon Mechanical Turk)
- Out-sourcing the task to unpaid fellow academic researchers
In the end, Karpathy decided to perform all of the task on his own to reduce labelling inconsistencies between human labellers.
In the end I realized that to get anywhere competitively close to GoogLeNet, it was most efficient if I sat down and went through the painfully long training process and the subsequent careful annotation process myself.
Karpathy stated that it took him roughly 1 minute to recognize each image for the 1,500 images in the smaller test set. By contrast, modern convolutional neural networks can recognize objects in images in under a second with a decent GPU. If we had to recognize the full test set of 100,000 images? Although developing a computer vision pipeline requires development time and specialized expertise, computers can perform visual recognition more consistently than humans without being fatigued and scale better when needed.
How?
To a computer, images are 2D arrays of pixel intensities. If the image is black and white, there is one channel per pixel. If the image is colour, there are (usually) three channels per pixel. If the image is from a video, then there is a time component as well. Since arrays are easily manipulated mathematically (cf. linear algebra), we can develop quantitative ways of detecting what is present in the images.
Hand-tuned Approach
For example, let’s say we wanted the computer to detect whether a handwritten number in an image is a 0 or a 1. We know that 0’s are curvier than 1’s, so we take the image arrays and fit a line through the strokes. Then, we find the curvature of these lines and pass it through a threshold to determine whether it’s a 0 or a 1.

I have a theory…that 0s are curvy lines and 1s are straight lines. This is known as the “hand-tuned approach”, because it requires a human operator to develop a rule-based theory of how to detect a given pattern that a computer can understand. It is probably the most obvious way of performing computer vision. But while it works for simple problems like recognizing simple digits and letters, it quickly falls apart once you give it a more complicated image with lighting variations, background, occlusion, and viewpoint variations.
Machine Learning Approach
This is where the “machine learning approach” comes in. Simply put, machine learning is the development of algorithms on a set of labelled training data which will then (hopefully) perform well on a set-aside test set during deployment. In general, the more complicated the data to learn, the more complicated the model also needs to be.
For example, say you wanted to detect whether an image contained a dog or a cat. At training time, you get a large collection of images labelled as either dog or cat. You take an algorithm and train it until it can recognize most of these training images well. To check if it still works well on unseen images, you give it new images of dogs and cats and verify how well it performs.

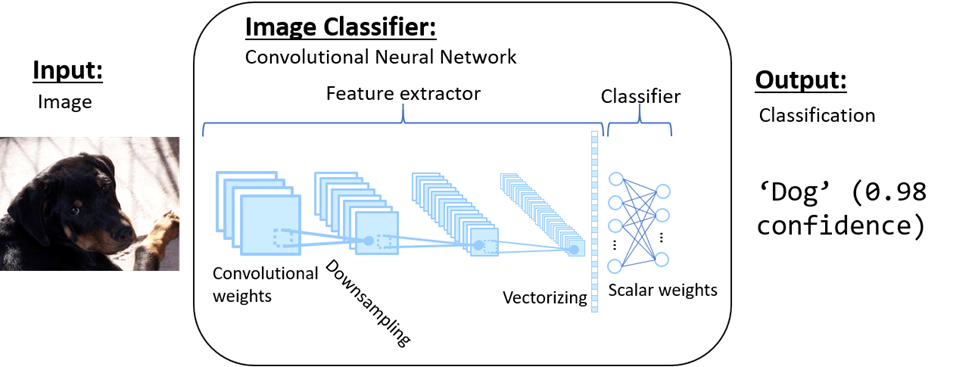
The “boom” in machine learning in recent years is actually a boom in what are known as “deep learning” models. These models use layers of learnable weights to extract features and classify, whereas previous models used hand-tuned features and shallow learnable weights to classify them. As we mentioned before, one of the most fundamental models in computer vision is known as the “convolutional neural network” (CNN or ConvNet for short). These models extract features from the image by repeatedly convolving (think of this as a 2D multiplication) it with 3D weights and downsampling. Then, the features are converted into a 1D vector and multiplied with scalar weights to produce the output classification.
(Core) Computer Vision Tasks
Since the human visual system performs many different tasks at the same time and computer vision is supposed to replicate it, there are many ways to break it down into discrete tasks. In general, the core tasks computer vision tries to solve are the following (in order of increasing difficulty):

Source: Medium
- Image Classification: given an image with a single object, predict what object is present (useful for tagging, searching, or indexing images by object, tag, or other attributes)
- Image Localization: given an image with a single object, predict both what object is present and draw a bounding box around it (useful for locating or tracking the appearance or motion of an object)
- Object Detection: given an image with multiple objects, predict both which objects are present and draw a bounding box around each object instance (useful for locating or tracking the appearance or motion of multiple objects)
- Semantic Segmentation (not shown in figure): given an image with multiple objects, predict both which objects are present and predict which pixels belong to each object class (e.g. the cat class) (useful for analyzing the shape of multiple object classes)
- Instance Segmentation: given an image with multiple objects, predict both which objects are present and predict which pixels belong to each instance (e.g. cat #1 vs. cat #2) of an object class (useful for analyzing the shape of multiple object instances)
Available Datasets and Models
Just as ILSVRC provided already-annotated data (ImageNet) to objectively compare algorithms from different researchers, the competing researchers in turn released their models to back up their claims and promote further research. This culture of open collaboration means that many state-of-the-art datasets and models are openly available to the general public for use and the top models can be readily applied without even requiring re-training.
Of course, if the objects one needs to recognize are not covered under “tape_player” and “grey_whale” (perhaps “machine_1” or “door_7”), it will be necessary to collect custom data and annotations. But in most cases, the state-of-the-art models can simply be retrained with the new data and still perform well.
| Task | Datasets | Sample Annotated Image | State-of-the-Art Model with Code (at time of writing) |
| Image Classification (single label) | ImageNet
(e.g. tape_player, grey_whale) |
 |
FixEfficientNet-L2 (2020), top-1 accuracy=88.5% |
| Object Localization (multiple bounding boxes) | KITTI Cars
(e.g. car bounding boxes, orientation) |
 |
Frustum PointNets (2017), AP=84.00% |
| Semantic Segmentation (multiple class segments) | PASCAL Context
(e.g. grass, table) |
 |
ResNeSt-269 (2020), mIoU=58.9% |
| Instance Segmentation (multiple instance segments) | CityScapes
(e.g. road, person) |
 |
EfficientPS (2019), AP=39.1% |
Possible Business Use-Cases
Now that we have gone through what computer vision is, why it is useful, and how it is performed, what are some potential applications for businesses? Unlike text or database records, images are typically not well catalogued and stored by companies. However, we believe that certain companies in specialized fields would have the data and motivation to benefit from using computer vision to extract extra value from their stored image data.
Industrial
The first field is the manufacturing, resource extraction, and construction industry. These companies typically work on manufacturing products, extracting resources, or constructing civil works in large quantities and many of the monitoring or predictive analytics are done manually or with simple analytical techniques. However, we think that computer vision would be useful for automating the following tasks:
- Defect detection, quality control: by learning the appearance of normal products, a computer vision system could flag a machine operator once it detects a likely defect (e.g. Ai Maker, from AiBuild)

Source: 3D Printing Industry
- Predictive maintenance: by learning the appearance of a given machinery near the end of its operational life, a computer vision system could monitor the machinery in real time, quantify its state (e.g. 90% strength), and forecast when it will need maintenance
- Remote measurement: by learning to draw a bounding box around an object of interest (e.g. a crack in a material), a computer vision system could determine the real-world size of that object
- Robotics: by learning to recognize objects in its field of view, a computer vision system embedded inside a robot could learn to manipulate objects (e.g. in a factory) or navigate its environment
Medical
The medical field is a similar field that could benefit from computer vision, since much of the work centres around monitoring and measuring the physical state of human patients (instead of machinery or manufactured products).
- Medical diagnostic aids: by learning the appearance of tissues of diagnostic interest to doctors, a computer vision system could suggest relevant regions and speed up diagnosis (e.g. segmenting histological tissue types from pathology slides with HistoSegNet)
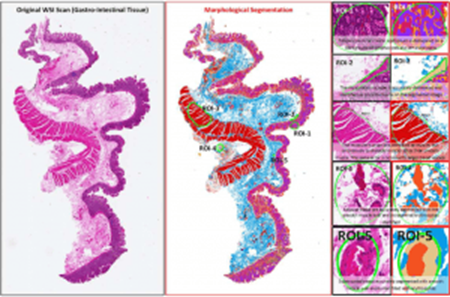
HistoSegNet, from the author’s time in academia 😁 Source: Chan et al. (2019) [5]
- Remote measurement: again, by learning to draw a bounding box around an object of interest (e.g. a lesion), a computer vision system could determine the real-world size of that object for monitoring a patient’s progression over time (e.g. Swift Skin and Wound, from Swift Medical)

Source: Swift Medical
Documents and Multimedia
Documents and multimedia are another field that could benefit from computer vision because of the vast quantity of unstructured (and un-annotated) information that most companies hold in the form of scanned documents, images, and videos. Although most companies tend not to label these images, some might have useful tags that could be exploited (e.g. an online retail store’s product information).
- Optical Character Recognition (OCR): scanned documents can have their text recognized and extracted for further processing
- Image search engine: images can be used to search for other images (e.g. for an online retail website, search for visually-similar products or stylistically-similar products to the most recently purchased product)
- Visual Question Answering (VQA): users can ask the computer vision system questions about the scene depicted in an image and receive a human-language response – this is important for video captioning (e.g. “What is Bob doing on the ground?” > “Bob is sleeping on the ground.”)

Source: Goyal et al. (2017) [6]
- Video summarization: a computer vision system can summarize the events in a video and return a concise summary – this is important for automatically generating video descriptions (e.g. “A man is giving a talk to a crowd of listeners before being interrupted by a dog that runs in.”)
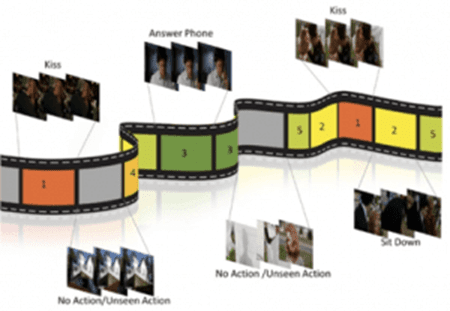
Source: Kourosh Meshgi
Retail and Surveillance
Retail (which we touched on in previously) and surveillance are other fields that could benefit from computer vision. They rely on monitoring human actors and their behaviour in real time to optimize a desired outcome (e.g. purchasing behaviour, illegal behaviour). If the behaviour can be observed visually, computer vision can be a good solution.
- Human Activity Recognition: a computer vision system can be trained to identify a human’s current activity in a video feed (e.g. walking, sitting), which can be useful for quantifying the number of people sitting in a crowd or identifying crowd flow bottlenecks
- Human Pose Estimation: a computer vision system can also be trained to localize the position and orientation of a human’s joints, which can be useful for virtual reality interactions, gesture control, or analyzing a person’s motions for medical or sports purposes
- Indoor Visual Localization: a computer vision system can be used to match a current real-time image or video feed of an indoor environment with a database of known snapshots and locate the current user’s position in that indoor environment (e.g. a user takes a picture in a university campus and an app shows them where they are)
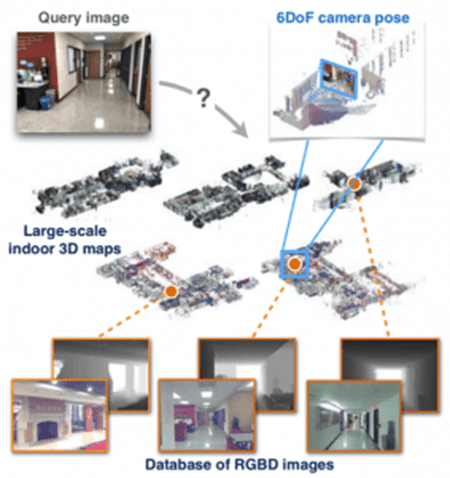
Source: Taira et al. (2018) [7]
Satellite Imagery
Satellite imagery is the final field that we could see computer vision being useful, since it is often used to monitor land use and environmental changes over time through tedious manual annotation by experts. If trained well, computer vision systems could speed up real-time analysis of satellite imagery and assess which regions are affected by natural disasters or human activity.
- Ship/Wildlife Tracking: from satellite imagery or a port or wildlife reserve, a computer vision system could quickly count and locate ships and wildlife without needing tedious human annotation and tracking
Source: Kellenberger et al. (2019) [8]
Source: Gabriel Garza
- Crop/Livestock Monitoring: a computer vision system could also monitor the state of agricultural land (e.g. by locating diseased or low-yield areas) to optimize the allocation of pesticide use and irrigation
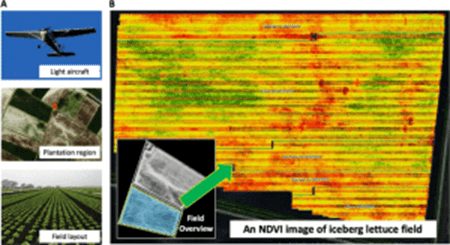
Source: Bauer et al. (2019) [9]
Practical Considerations
You see, computer vision has lots of exciting applications for businesses. However, before jumping on the bandwagon, businesses should first consider the following:
- Data: do you source the image data from a third-party, from a vendor, or collect it yourelf? Most digital data is either unusable or not analyzed
- Annotations: do you source the annotations from a third-party, from a vendor, or collect it yourself?
- Problem formulation: what sort of problem are you trying to solve? This is where domain expertise will come in handy (e.g. is it enough to detect when a machine is defective (image recognition) or do we also need to locate the defective areas (object detection)?)
- Transfer learning: can pre-trained models already do the job well enough (if so, there is less research and development work required)?
- Computational resources: do you have enough computing power for training/inference (computer vision models typically need cloud computing or powerful, local GPUs)?
- Human resources: do you have enough time or expertise to implement the models (computer vision typically needs machine learning engineers, data scientists, or research scientists with graduate-level education and enough working hours to dedicate themselves to working on research problems)?
- Trust issues: does the end-user / customer trust the computer vision approach? Good relationships must be established and explainability methods implemented to ensure transparency and accountability, which in turn promote higher user acceptance
References
[1] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. https://arxiv.org/abs/1409.0575, 2015.
[2] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. Conference on Neural Information Processing Systems (NeurIPS), 2012.
[3] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going Deeper with Convolutions. https://arxiv.org/abs/1409.4842, 2014.
[4] Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and Harnessing Adversarial Examples. https://arxiv.org/abs/1412.6572, 2015.
[5] Lyndon Chan, Mahdi S. Hosseini, Corwyn Rowsell, Konstantinos N. Plataniotis, and Savvas Damaskinos. HistoSegNet: Semantic Segmentation of Histological Tissue Type in Whole Slide Images. International Conference on Computer Vision, 2019.
[6] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. https://arxiv.org/abs/1612.00837, 2017.
[7] Hajime Taira, Masatoshi Okutomi, Torsten Sattler, Mircea Cimpoi, Marc Pollefeys, Josef Sivic, Tomas Pajdla, Akihiko Torii. InLoc: Indoor Visual Localization with Dense Matching and View Synthesis. Conference on Computer Vision and Pattern Recognition, 2018.
[8] Benjamin Kellenberger, Diego Marcos, and Devis Tuia. When a few clicks make all the difference:Improving weakly-supervised wildlife detection in UAV images. Conference on Computer Vision and Pattern Recognition, 2019.
[9] Alan Bauer, Aaron George Bostrom, Joshua Ball, Christopher Applegate, Tao Cheng, Stephen Laycock, Sergio Moreno Rojas, Jacob Kirwan, and Ji Zhou. Combining computer vision and deep learning to enable ultra-scale aerial phenotyping and precision agriculture: A case study of lettuce production. Hortic Res 6, 70. https://doi.org/10.1038/s41438-019-0151-5, 2019.

