
Ask and the machine will answer 🤔 … a demo of an AMA search engine developed on top of OpenAI’s state-of-the-art GPT-3 model. Source: @paraschopra
What is natural language processing (NLP)? What sort of data does it operate on? And how is it different from classical text analysis tools? Why use it? What sort of tasks belong to NLP and what are some potential business use-cases for each? What is possible with today’s technology? And what tools are available online to implement NLP for your own purposes?
This is the second article in our Machine Learning for Business Use-Cases series. If you haven’t already, check out our first article on Computer Vision.
What is Natural Language?
Human (or natural) language is a very complex and fascinating tool in our human toolkit. According to Chris Manning, Professor in Machine Learning at Stanford University, human language is a “discrete/symbolic/categorical signaling system … constructed to convey speaker/writer’s meaning”. Of course, other animals are capable of communicating meaning as well with each other through cries, squeaks, gestures, and chemical signals. But only humans are able to convey complicated abstract concepts through sound (an audio signal), gesture (a visual signal), and writing (a textual signal).
For the most part, when we talk about natural language processing, the natural language part refers to the writing portion of human language. Think of the “Translate by speech” feature on Google Translate and how it essentially consists of two steps: (1) converting your speech to text and (2) converting the text to the target language. Speech is an important part of human communication of course, but far more information in the modern age is conveyed through writing rather than speech. Indeed, speech and writing can often be converted between one another. For the rest of this article, we will be focusing on the written, textual aspect of natural language.
What is textual data?

Source: Pexels
Once textual language has been digitally encoded, it can be stored and interpreted for further analysis. One simple way to understand it is to explore its relationships with other types of data. Broadly speaking, data can be classified under two types – structured and unstructured. Text is (usually) running text without any pre-defined metadata attached, so it is unstructured and hard to query.
- Structured Data: data that is structured with a pre-defined schema – these are easy to query!
- Simple databases: CSV, Microsoft Excel
- Relational databases (RDBMS): use a tabular schema and often use SQL for querying and maintenance
- Enterprise-class: Oracle, Microsoft SQL Server, MySQL, PostgreSQL
- Lightweight: SQLite, MariaDB
- Non-relational databases (NoSQL): use a non-tabular schema
- Wide column store: Amazon DynamoDB, Cassandra
- Document store: MongoDB
- Multi-model database: OrientDB
- Graph: Neo4j
- Unstructured Data: data that has some internal structure (i.e. it is interpretable by humans) is not structured with a pre-defined schema – these are generally difficult to query (unless some structured metadata is attached)!
- Images
- Video
- Audio
- Text
Wait … isn’t text easy to deal with?

Source: Calvin and Hobbes, via Arnold Zwicky
Let’s step back for a moment. Can’t you just search for a keyword in a text document? How is text considered difficult to query?
Well, yes and no. Natural language lies on a spectrum of complexity. On the lower end, we have a smaller vocabulary (lexicon), a less diverse grammar (syntax), and simpler concepts (semantics, ontology). This simpler end of language is populated by short, structured commands often specialized for a very particular use-case. For example, a child might say, “I want cookie” or you might say “Hey Google, play me the soundtrack for Arrival.” The more complex end of language contains those texts that give you headaches when learning a foreign language and require lots of experience and even cultural knowledge to pick out the variations and nuances. For example, we might have natural dialogue filled with slang and jokes or technical government documents or elegant poetry.
On the simpler end, it will probably be enough to use keyword matching. But on the complex end, as many a language learning knows only too well, only the deeper meaning will do.
An example – retrieving customer calls about service disruptions

Source: Pexels
Let’s say you are a call centre and have collected a large database of call transcripts in text form (i.e. unstructured data) recorded from customer complaints. Now let’s also say you want to retrieve all customer calls regarding service disruptions.
The simple method is just to do a keyword search for “service disruption” in your giant database. That might work decently well, but how about those calls where the customer mentioned “disruption” without the word “service” or “outage” instead of “disruption”? What if service disruptions aren’t even mentioned in the transcript but they keep mentioning “doesn’t work”? These are common real-world scenarios where the unstructured data you’ve collected (and the customers they come from) do not operate exactly as you expected.
Solution #1: Fix the Data
One way to fix this mismatch is to simply annotate the call transcripts with metadata. For example, you would tag the calls mentioning “service outage” as being about “service disruption” too. This approach would essentially convert your unstructured text data into structured data which will be stored as either a relational or non-relational database. The problem is that this approach requires intensive manual annotation and is restricted to a fixed tagging schema. What if you decide a year later to divide the “service disruption” category into “dropped calls” and “power outages”? Good luck going back and fixing everything.
Solution #2: Fix the Search Method
Another solution is to keep the unstructured text the way it is and improve your method of querying. For example, when you search for “service disruption”, the system would then retrieve all calls with similar topics to “service disruption”.
While the former solution is a more traditional text analysis approach based on keywords, the latter solution is the natural language processing (NLP) solution based on analyzing the semantic meaning behind the texts. Because the NLP way does not require a pre-defined schema, it is more flexible and robust to future changes in the data.
What is Natural Language Processing?

“I am C-3PO, human-cyborg relations.” 🧍🔗🤖Source: Unsplash
So what is natural language processing? It appears most people define it in one of two ways:
- The computer-centric view: it is the automatic manipulation of natural language by computers (cf. the analogous definition of computer vision)
- The human-centric view: it is the use of natural language to mediate human-computer interaction (in the way that, say, a keyboard allows a human to interact with a computer)
What’s difficult about NLP?
As we mentioned earlier, natural language is often filled with nuances and ambiguities, slang, and mistakes. Oftentimes, the context requires outside knowledge that is difficult for computers to incorporate. And language is part of a social system – people use language to persuade, amuse, or satirize. Even worse, language can be used for malicious purposes.
In 2016, Microsoft launched an artificial intelligence-driven Twitter chatbot aimed at improving millennial engagement. Called “Tay”, it was built to “engage and entertain people where they connect with each other online through casual and playful conversation”. However, as its creators noted, “The more you chat with Tay the smarter she gets” and within hours of its launch, malicious Twitter users taught it to spew racist content and conspiracy theories.
What’s easy about NLP?

Sometimes, simple is good enough. Source: Imgur
The good news though, is that NLP works well for many use-cases and oftentimes, even rough features will do. The more structure, simplicity, and uniformity there is in the text, the more suitable it will be for NLP.
Why use NLP?

And what better way to deal with it than NLP? Source: Make a Meme
Like any other “computational” field, NLP is useful because computers can do quantitative tasks without fatigue and far more consistently and scalably than humans can. Furthermore, as we wrote before, only a small portion of digital data (<5%) is actually analyzed. Currently, most companies store their data in databases with fixed schemas for later analysis. But how about the vast amounts of unstructured human-readable text that isn’t stored in databases? NLP enables companies to either analyze their textual data without needing a pre-defined schema or else convert it into traditional structured databases for analysis.
Social media giants like Facebook, Twitter, and Youtube (under Alphabet) have long utilized NLP technologies to supplement human moderators in detecting abuse, hate speech, and exploitation on their platforms. Content moderation is a mentally taxing task and problematic content can often be even traumatic for human moderators.
Approaches to NLP
Broadly speaking, there are two main approaches you can take for NLP:
Rule-based Approach
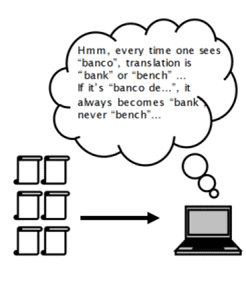
In the rule-based approach, the system processes the text based on a hand-tuned grammar. This is a “prescriptive” way of looking at language and encodes what language should be.
It requires expert knowledge to develop the rules, little training data, and works well for simple texts with little variation. This is typically how students are taught foreign languages in a classroom setting, with grammatical rules presented systematically over time.
Statistical Approach
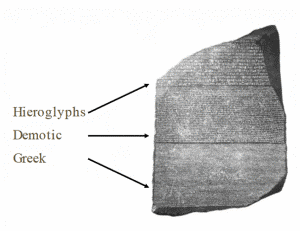
The Statistical approach observes rules in the text and applies it to new texts. Source: CS224n
The statistical approach, on the other hand, processes the text based on observed rules. This is a “descriptive” way of looking at language and computationally encodes what language is observed to be.
It does not require expert knowledge but requires lots of training data to work well with complex and varied texts. This is the approach taken by linguists to learn Ancient Egyptian hieroglyphics from the Rosetta Stone, which contained a trilingual text correspondence between the well-known Ancient Greek and undeciphered Demotic and Egyptian hieroglyphic scripts.
NLP Tasks

Source: Pexels
The tasks addressed by NLP can be divided into three broad categories in order of increasing difficulty and complexity: pre-processing, low-level, and high-level tasks. Oftentimes, the lower level tasks are stepping stones to solving higher level tasks.
Pre-Processing Tasks
Normally, a raw text is formatted to make subsequent NLP tasks easier with the following five steps. We will use a sample two-sentence text to illustrate how they work:
The quick brown fox jumps over the lazy dog. Waltz, bad nymph, for quick jigs vex.
-
- Tokenization: splits the text into smaller pieces, such as sentences
- e.g. {“The quick brown fox jumps over the lazy dog.“, “Waltz, bad nymph, for quick jigs vex.”}
- Normalization: converts the text to the same format, such as converting uppercase to lowercase
- e.g. {“the quick brown fox jumps over the lazy dog.”, “waltz, bad nymph, for quick jigs vex.”}
- Noise Removal: removes invalid or non-text characters, such as punctuation
- e.g. {“the quick brown fox jumps over the lazy dog
.“, “waltz,bad nymph,for quick jigs vex.“}
- e.g. {“the quick brown fox jumps over the lazy dog
- Stopword Removal: removes very common words with little meaning, such as “the”, “over”, or “for” (note that this is sometimes not desirable for NLP problems where such words are meaningful)
- e.g. {“
thequick brown fox jumpsoverthelazy dog”, “waltz bad nymphforquick jigs vex”}
- e.g. {“
- Lemmatization: converts words to their base forms, such as “jumps” to “jump”
- e.g. {“quick brown fox jump lazy dog”, “waltz bad nymph quick jig vex”}
- Tokenization: splits the text into smaller pieces, such as sentences
Low-Level Tasks – Keyword Extraction
After pre-processing, simple rule-based methods (or even statistical methods sometimes) can be applied to the extracted keywords from the text. Let’s explore each low-level task and how it can be used for business use-cases.
- Part-Of-Speech (POS) tagging: labels each word by its grammatical role (i.e. part-of-speech)
- e.g. “And now for something completely different.” → {“And”: Coordinating conjunction, “now”: Adverb, “for”: Preposition, “something”: Singular noun, “completely”: Adverb, “different”: Adjective}
- Applications: usually a stepping stone for other, more advanced tasks (unless your goal is analyzing grammatical functions in a text)
- Named Entity Recognition (NER): locates and classifies named entities (e.g. persons, locations, organizations) into pre-defined categories
- e.g. “Jim bought 300 shares of Acme Corp. in 2006.” → {“Jim”: Person, “Acme Corp.”: Corporation, “2006”: Time}
- Applications: extracting events from a text, building a search engine, building a database of entities in a large collection of texts
- Relationship Extraction / Event Extraction: extract subject-verb-object triplets, actor-action pairs, or actor-object pairs from a text
- e.g. “Paris is the capital of France” → {Country: “France”, Capital city: “Paris”}
- e.g. “The United States won the most gold medals in the 2016 Olympics.” → {Subject: “United States”, Verb: “won”, Object: “gold medals”}
- Applications: populating a database (relational or non-relational) with a fixed schema (e.g. subject-verb-object, actor-action, actor-object) of company acquisitions, business news
- Document Classification / Clustering: label each document in a collection with a pre-defined class (classification) or cluster similar documents together without pre-defined classes (clustering)
- e.g. “The company’s revenues for 2020 Q1 grew by 52% …” → Financial report (classification)
- e.g. “The company’s revenues for 2020 Q1 grew by 52% …” → Cluster #2, which are mostly financial reports (clustering)
- Applications: automatically tagging or organizing a large collection of texts for routing to the correct employee, facilitating document search (e.g. in a library)
High-Level Tasks – Content Analysis
- Sentiment Analysis: quantifies the subjective sentiment of a text on a scale from 0 (most negative) to 1 (most positive)
- e.g. “I love Alphabyte Solutions.” → 0.92 sentiment (very positive)
- Applications: quantifying user responses to a given product where there are many text reviews and few or unreliable numerical ratings, analyzing a social media feed
- Recommender Systems: analyzes the content of an unstructured text to provide a content-based recommendation
- e.g. A user reads a book on the political system in Canada → the system recommends a book on the political system in the United States
- Applications: improving customer engagement of text-based products by recommending relevant products similar to query texts
- Natural Language Understanding: extracts the semantic meaning from a text (e.g. query) beyond keyword matching and (optionally) converts it into a database query
- e.g. “Which pandemics in the last 100 years had a greater death toll than COVID-19?” → “”SELECT Pandemics by death tollWHERE start date is between 1920 and 2020 AND death toll > COVID-19GROUP BY Pandemic nameSORT BY death toll DESC”
- Applications: building search engines that can take natural language queries, enabling non-technical users to easily query a database (e.g. Advanced Search on Google)
- Information Retrieval / Semantic Search / Question Answering: given a text query, retrieves content-relevant documents or returns a natural language answer
- e.g. “Which pandemics in the last 100 years had a greater death toll than COVID-19?” → “Spanish flu, Russian typhus, Asian flu, etc. all had the same death count as COVID-19 in the last 100 years.”
- Applications: building systems that can answer user questions in natural language (e.g. chatbots) or create a user-interactive FAQ tool
Available NLP Tools
For straightforward NLP tasks, off-the-shelf software libraries are a good choice to build a prototype pipeline.
- NLTK: entry-level NLP library for research and education (text classification, POS tagging, NER, etc.)
- CoreNLP: high-performance NLP library (information scraping, sentiment analysis, conversational interfaces, text generation)
- GenSim: excels in word vectorization (topic modelling, document similarity, semantic search, text generation)
- SpaCy: industrial-strength NLP library (sentiment analysis, conversational interfaces, word vectors)
- TextBlob: rapid-prototyping NLP library (sentiment analysis, event extraction, intent analysis, machine translation)

